Dr. Partha Majumder is a Gen-AI product engineer and research scientist with a Ph.D. from IIT Bombay. He specializes in building end-to-end, production-ready Gen-AI applications using Python, FastAPI, LangChain/LangGraph, and Next.js.
Core stack
Python, FastAPI, LangChain/LangGraph, Next.js
Applied Gen-AI
AI video, avatar videos, real-time streaming, voice agents
This part explains how CUDA’s “programmer view” (threads, blocks, and grids) turns into real work on the GPU. Once that mapping is clear, terms like SIMT, warps, and streaming multiprocessors stop feeling abstract—and it becomes much easier to understand why some kernels run fast and others slow down.
In this CUDA C++ tutorial chapter, we will cover:
How CUDA’s logical programming model maps to GPU hardware
The CUDA execution model (SIMT) and why warps matter
Warp divergence and a practical way to reduce it
How registers and shared memory limit occupancy (resource partitioning)
The CUDA execution model provides a way of thinking about how modern NVIDIA GPUs achieve parallel computing. This model reveals the underlying principles that make GPU parallelism possible and allows developers to design efficient, high-performance applications. So, it’s not just a theoretical concept but a practical guide to unleashing the full potential of GPU computing. In the following subsections, we will discuss CUDA execution model in detail.
Logical View Of CUDA Programming
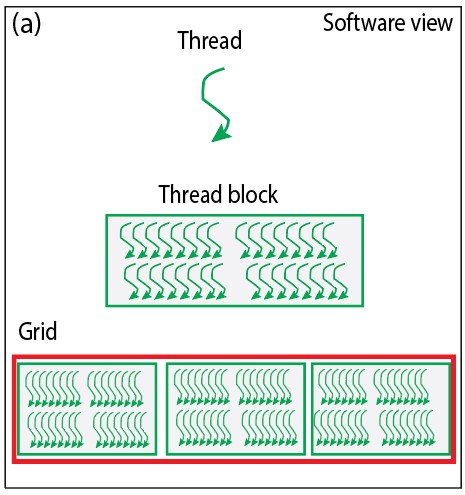
The Logical View of CUDA Programming offers a high-level, abstract perspective on the principles and concepts behind GPU-accelerated parallel computing. It focuses on fundamental concepts such as parallel threads, synchronization, memory hierarchy, data parallelism, and scalability, providing a conceptual framework for understanding CUDA development. This view is essential for grasping the design paradigms and strategies needed to harness the parallel computing power of NVIDIA GPUs effectively. Developers can use the Logical View to plan the architecture and parallelism of their applications without delving into low-level hardware details.
Hardware View Of CUDA Programming
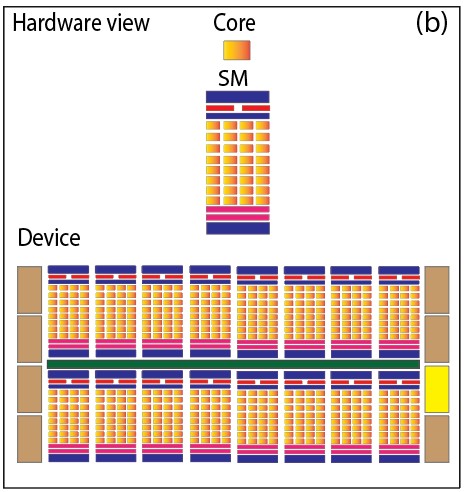
The Hardware View of CUDA Programming offers an in-depth understanding of the GPU architecture and hardware components that execute CUDA code. It covers the organization of Streaming Multiprocessors (SMs), core execution resources, and how threads are scheduled and executed at the hardware level. The figures below show a pictorial representation of the software view and the hardware view of CUDA programming (see Figure 1).
Fig. 1. (a) Software view of CUDA programming (b) Hardware view of CUDA programming
GPU Architecture Overview
Understanding GPU architecture is essential for CUDA programming because it enables efficient utilization of the hardware’s parallelism, memory hierarchy, and resources, leading to optimal performance gains and effective debugging.
The GPU’s architecture is structured around a flexible array of Streaming Multiprocessors (SMs), which is the fundamental unit for harnessing hardware parallelism. The figure below shows the key components of a Fermi SM (see Figure 2).
Streaming Multiprocessor (SM)
Each Streaming Multiprocessor (SM) in a GPU is designed to support concurrent execution of hundreds of threads.
There are typically multiple SMs within a single GPU.
When a kernel grid is launched, the thread blocks within that grid are distributed across the available SMs for execution.
Each SM takes on the responsibility of executing the threads from one or more thread blocks.
Threads within a thread block execute concurrently, but only on the assigned SM.
Once scheduled on an SM, all threads in a thread block execute on that SM.
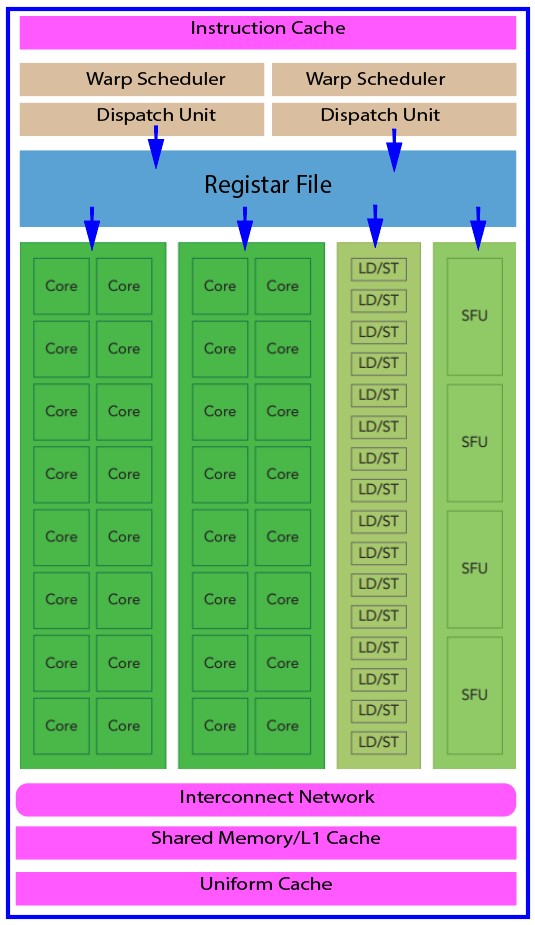
Fig. 2. Key components of a Fermi Streaming Multiprocessor (SM)
Let us discuss the key components of the Fermi SM shown above:
CUDA Cores: At the heart of the SM are the CUDA Cores, which are the workhorses responsible for performing the actual computation. These cores execute instructions concurrently, enabling the parallel processing capabilities of the GPU. With each new GPU generation, the number of CUDA Cores within an SM has significantly increased, enhancing the overall computational power.
Shared Memory/L1 Cache: Shared memory, often referred to as L1 cache, serves as a high-speed memory space that is shared among threads within a block. This memory is utilized for temporary data storage and is particularly valuable for data sharing among threads. Efficient use of shared memory is essential for optimizing performance in parallel algorithms. It acts as a buffer that reduces the time it takes to access data compared to fetching it from slower global memory.
Register File: Registers are tiny, ultra-fast memory storage units that play a crucial role in GPU computation. Each thread within a CUDA block has its own set of registers to hold thread-specific data. Registers are used to store variables, intermediate results, and other essential data. As registers are much faster to access than shared or global memory, they contribute to the overall speed and efficiency of the GPU’s parallel processing.
Load/Store Units (LD/ST): Load and store units are responsible for data transfers between global memory and the SM. Global memory is the largest and slowest memory in the GPU hierarchy, so efficiently managing data movement between global memory and the SM is critical for performance optimization. Load units fetch data from global memory, while store units write data back to it. Efficient memory access patterns and memory hierarchy management are crucial to minimizing data transfer overhead.
Special Function Units (SFU): Special Function Units (SFUs) are specialized hardware units within the SM that handle various mathematical and logical operations. These include operations like sine, cosine, and square root calculations, as well as logical operations like bitwise AND, OR, and XOR. SFUs significantly accelerate the execution of specific operations, especially in applications that heavily rely on trigonometric functions or advanced mathematical computations.
Warp Scheduler: The Warp Scheduler is a critical component responsible for orchestrating the execution of threads within an SM. Threads are grouped into units known as warps. These warps are typically composed of 32 threads. The Warp Scheduler schedules the warps to ensure that they are executed efficiently, managing thread execution, and handling latency by switching to different warps when waiting for data. This dynamic scheduling is essential for hiding memory access latencies and maximizing SM utilization.
Single Instruction Multiple Threads (SIMT)
SIMT, or Single Instruction, Multiple Threads, is a parallel execution model used in modern GPU (Graphics Processing Unit) architectures.
In the SIMT model, a large number of threads work concurrently, executing the same instruction stream, but they can diverge along different execution paths based on conditional statements.
This flexibility allows SIMT to efficiently handle tasks with diverse data and conditional requirements, making it well-suited for applications like graphics rendering, simulations, and parallel computing.
SIMT is a key feature of GPU computing, enabling high levels of parallelism and computational efficiency.
Example of SIMT
Imagine a classroom where a teacher hands out math worksheets to students. Each student receives a unique pair of numbers, and the task is to find the product of those two numbers.
The teacher provides the same set of multiplication instructions to all students, and they execute these instructions independently using their individual number pairs.
Additionally, the teacher instructs the students that if one of the numbers is negative, they should perform a subtraction instead of multiplication.
In this scenario, the teacher’s instructions represent a single instruction (SIMT model), and the students execute these instructions concurrently but with different data (their unique number pairs) and some variation in execution based on the provided rule. This reflects the SIMT execution model found in GPUs, where multiple threads execute the same instruction but with divergent control flow when needed.
Why SIMT is Different from SIMD?
SIMT (Single Instruction, Multiple Threads) and SIMD (Single Instruction, Multiple Data) are both parallel execution models, but they exhibit distinct characteristics that set them apart in the world of parallel computing. Understanding these differences is essential for optimizing GPU programming.
Control Flow Flexibility
In SIMT, threads within the same warp (a group of threads that execute in lockstep) can follow different control flow paths based on conditional statements. This flexibility allows each thread to make independent decisions during execution.
In contrast, SIMD mandates that all threads adhere to the same control flow path, which can be limiting when dealing with diverse conditional scenarios.
Divergent Execution
SIMT accommodates divergent execution, where threads within a warp can execute different code branches. This feature is particularly useful when threads encounter conditional statements, as it ensures that each thread proceeds according to its specific conditions.
SIMD, on the other hand, struggles with divergence. When some threads within a group follow a different code branch, SIMD requires these threads to wait for the others, resulting in suboptimal performance.
Flexibility in Thread Management
SIMT allows dynamic thread management, with threads entering and exiting warps as needed. This adaptability optimizes resource utilization and contributes to better load balancing.
SIMD has fixed-size vectors, and threads are statically allocated to these vectors. This rigidity can lead to inefficient resource usage and a less adaptable execution model.
Applicability to Real-World Scenarios
SIMT is well-suited for applications with varying execution paths, such as image processing, scientific simulations, and machine learning. Its ability to handle diverse and dynamic conditions makes it an excellent choice for these workloads.
SIMD shines in scenarios where all threads perform the same operations on large datasets simultaneously, such as in multimedia processing or certain scientific computations. However, it may struggle in applications requiring conditional execution.
What is Warp?
A warp is a group of threads that execute instructions in a coordinated manner. These threads operate in a SIMT (Single Instruction, Multiple Threads) fashion, meaning that they execute the same instruction simultaneously.
In modern NVIDIA GPU architectures, a warp typically consists of 32 threads. This means that there are 32 threads in a warp, and all of them execute the same instruction at the same time.
Relationship Between Warps and Thread Blocks
When a kernel is launched, the GPU scheduler groups threads into warps. If the total number of threads in a thread block is not a multiple of the warp size (e.g., 32 threads), some warps may be only partially filled.
Warps are the units that the GPU scheduler uses to issue instructions to the execution units. Each warp is scheduled on a streaming multiprocessor (SM) for execution.
Threads within a warp execute in SIMT fashion, meaning they execute the same instruction at the same time but with different data. While threads within a warp execute the same instruction, different warps can execute different instructions.
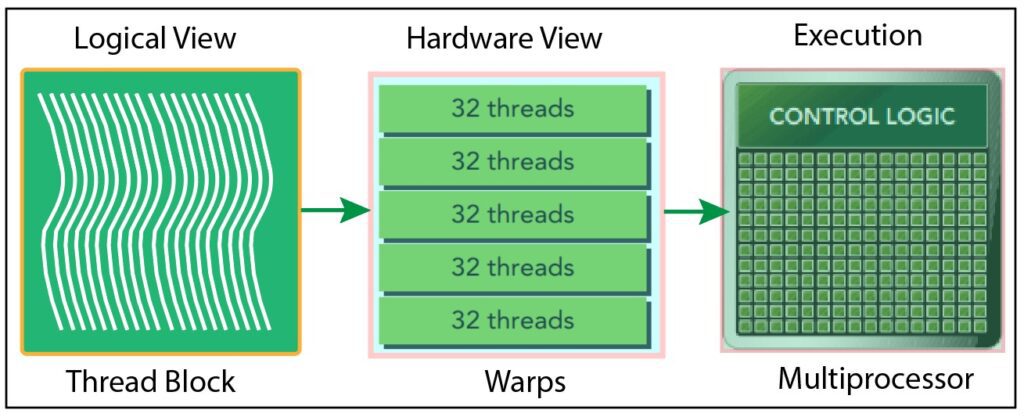
The figure below illustrates how the logical view and hardware view of a thread block are connected (see Figure 3).
Fig. 3. Logical view and hardware view of a thread block
Warp Divergence
In CUDA, a warp is a fundamental unit of thread execution: a group of threads that are scheduled together and execute in lockstep. When all threads in a warp follow the same control flow, the hardware can make steady forward progress and keep the SM busy.
Warp divergence occurs when threads within the same warp take different paths due to conditional logic. For example:
If half the threads in a warp go down “Code block A” while the other half goes down “Code block B,” this is where divergence happens. If threads of a warp diverge, the warp serially executes each branch path, disabling threads that do not take that path.
The key consequence is inefficiency: the warp serially executes each branch path, temporarily disabling threads that are not on the active path. This reduces effective parallelism and can noticeably slow kernels down. The code below demonstrates this pattern.
#include <iostream>using namespace std;const int N = 64;const int warpSize = 32;__global__ void warpDivFunction(float* c) { int tid = blockIdx.x * blockDim.x + threadIdx.x; float a, b; a = b = 0.5f; // Check for warp divergence if (tid % 2 == 0) { a = 1.0f; // Threads with even thread IDs set 'a' } else { b = 100.0f; // Threads with odd thread IDs set 'b' } c[tid] = a + b;}int main() { float* h_c = new float[N]; float* d_c; // Allocate device memory for the result cudaMalloc((void**)&d_c, N * sizeof(float)); // Launch the warpDivFunction kernel with N threads warpDivFunction<<<1, N>>>(d_c); // Copy the result back to the host cudaMemcpy(h_c, d_c, N * sizeof(float), cudaMemcpyDeviceToHost); // Print the result for (int i = 0; i < N; ++i) { cout << h_c[i] << " "; } // Clean up allocated memory delete[] h_c; cudaFree(d_c); return 0;}
The code defines a CUDA kernel function named warpDivFunction that operates on an array c. It’s designed to illustrate warp divergence. Each thread, identified by its tid (thread ID), initializes two float variables a and b with values of 0.5.
Within the kernel, a check for warp divergence is implemented using if (tid % 2 == 0). When tid is even (threads with even thread IDs), it sets a to 1.0f, and when tid is odd (threads with odd thread IDs), it sets b to 100.0f. This demonstrates that threads within the same warp might execute different instructions, leading to warp divergence.
In the main function, the code allocates memory for the result on the device, launches the warpDivFunction kernel with N threads, copies the result back to the host, and prints the values to the console.
The main takeaway here is that when threads within a warp take different code paths, it can lead to inefficiencies due to serialization of execution, which can impact the overall performance of a CUDA application.
In many cases, divergence can be reduced by aligning branching with warp boundaries. In the warp-centric approach, the condition uses (tid / warpSize) % 2 == 0 instead of (tid % 2 == 0), which makes entire warps follow the same branch. The code below shows the updated approach.
#include <iostream>using namespace std;const int N = 64;const int warpSize = 32;__global__ void warpDivFunction(float* c) { int tid = blockIdx.x * blockDim.x + threadIdx.x; float a, b; a = b = 0.5f; // Check for warp divergence if ((tid / warpSize) % 2 == 0) { a = 1.0f; // Threads in even warps set 'a' } else { b = 100.0f; // Threads in odd warps set 'b' } c[tid] = a + b;}int main() { float* h_c = new float[N]; float* d_c; // Allocate device memory for the result cudaMalloc((void**)&d_c, N * sizeof(float)); // Launch the warpDivFunction with N threads warpDivFunction<<<1, N>>>(d_c); // Copy the result back to the host cudaMemcpy(h_c, d_c, N * sizeof(float), cudaMemcpyDeviceToHost); // Print the result for (int i = 0; i < N; ++i) { cout << h_c[i] << " "; } // Clean up allocated memory delete[] h_c; cudaFree(d_c); return 0;}
The code defines a CUDA kernel function named warpDivFunction intended to demonstrate warp divergence.
It operates on an array c and initializes two float variables, a and b, to 0.5 for each thread. It then calculates a unique tid (thread ID) for each thread based on its block and thread indices.
Within the kernel, the code checks for warp divergence using the condition if ((tid / warpSize) % 2 == 0). If this condition is met (even thread IDs), it sets a to 1.0f, and if it’s not met (odd thread IDs), it sets b to 100.0f.
In the main function, the code allocates memory for the result on the GPU, launches the warpDivFunction kernel with N threads, copies the result back to the host, and prints the computed values.
The condition (tid / warpSize) % 2 == 0 ensures that branching aligns with warp-sized segments, resulting in even warps executing the “if” clause while odd warps follow the “else” clause. This approach establishes branch granularity in multiples of the warp size.
Resource Partitioning
Resource partitioning in a GPU primarily involves the allocation and management of two crucial hardware resources: registers and shared memory. These resources play a fundamental role in how parallel tasks are executed on a GPU, and efficiently managing them is key to achieving optimal performance in parallel computing. Let us discuss them one by one.
Registers
Registers are small, high-speed memory locations within the GPU. Each thread within a thread block is allocated a certain number of registers for storing local variables and data. However, the total number of registers available per thread block is limited by the GPU’s architecture.
If threads consume a more number of registers, it can limit the number of active threads within a thread block.
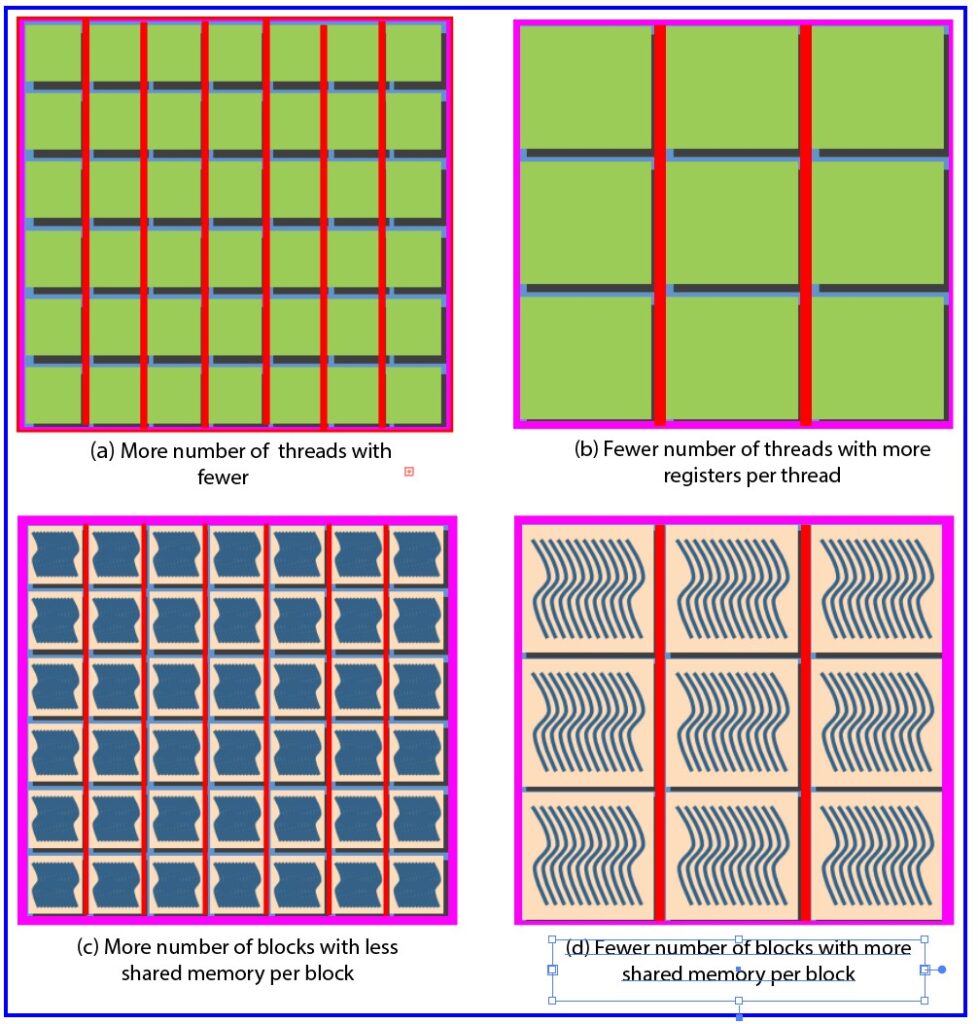
When each thread consumes fewer registers, more warps can be placed on an SM (see Figure 4(a)). When each thread consumes more registers, fewer warps fit concurrently (see Figure 4(b)).
Optimizing register usage is important to maximize the number of active threads and achieve better parallelism, ultimately leading to improved GPU performance.
Shared Memory
Shared memory is a fast, on-chip memory space available in each multiprocessor (SM) of a GPU. It is used for communication and data sharing among threads within the same thread block.
Like registers, the amount of shared memory available is limited for each SM. If each thread block consumes a small amount of shared memory, more thread blocks can be resident on an SM (see Figure 4(c)).
When a thread block consumes more shared memory, fewer blocks run concurrently on an SM, which can lead to underutilization (see Figure 4(d)).
Effective management of shared memory is vital to ensure that multiple thread blocks can coexist on an SM, maximizing parallelism and GPU performance.
The figure below summarizes the resource partitioning idea visually (see Figure 4).
Fig. 4. Pictorial representation of resource partitioning (register pressure and shared memory usage)
Latency Hiding
Latency hiding is a critical aspect of GPU programming, primarily in the context of parallel computing using NVIDIA’s CUDA C++ framework. It refers to the ability to mask or reduce the impact of high-latency operations, such as memory transfers or instruction pipeline stalls, by overlapping them with other useful computation. By doing so, applications can continue to make progress while waiting for these operations to complete, thereby improving overall throughput and minimizing the time wasted due to latency.
In CUDA programming, latency hiding is particularly important because GPUs are designed to handle massive parallelism. However, they often consist of thousands of lightweight processing cores, which means that they can execute a large number of threads simultaneously. To harness the full power of a GPU, developers must ensure that these threads remain active and productive.
The Significance of Latency Hiding
Understanding why latency hiding is crucial in CUDA C++ development is the first step toward effective GPU optimization. Latency in computing refers to the delay or time gap between the initiation of a request and the receipt of the corresponding response. This delay can be caused by various factors, including memory access times, data transfer between the CPU and GPU, or pipeline stalls due to dependencies.
The significance of latency hiding can be summarized as follows:
Improved Utilization: In a highly parallel environment like a GPU, efficient resource utilization is paramount. When one thread is stalled due to latency (e.g., waiting for data to be fetched from memory), other threads can continue executing. Latency hiding ensures that the GPU cores are actively processing threads, thus improving overall throughput.
Reduced Bottlenecks: By overlapping latency-prone operations with productive computations, developers can alleviate bottlenecks that would otherwise limit the GPU’s performance. This is especially critical when dealing with memory-bound applications.
Real-Time Responsiveness: Latency hiding is vital in applications where real-time responsiveness is required. By minimizing delays, tasks can be completed more quickly, making latency-sensitive applications, such as simulations and image processing, more efficient.
Optimized GPU Performance: To maximize the capabilities of a GPU, it is essential to keep the processing units active. Latency hiding helps in achieving high GPU utilization, which is vital for demanding tasks like deep learning, scientific simulations, and data processing.
Techniques for Latency Hiding
Here are brief descriptions of latency hiding techniques in CUDA GPU.
Asynchronous Execution: This technique involves launching GPU tasks asynchronously, allowing the CPU to initiate tasks and proceed with other computations without waiting for the GPU to finish. It enables overlapping CPU and GPU computations to hide latency effectively.
Overlapping Communication and Computation: Overlapping communication, such as data transfers, with computation is a strategy to minimize latency. By initiating data transfers and GPU computations in parallel, the GPU can process data while the transfer is in progress.
Shared Memory and Register Spilling: Using shared memory to reduce global memory access and spilling registers to slower memory when the kernel uses more registers than available on a multiprocessor. These techniques help minimize latency by optimizing memory access.
Dynamic Parallelism: Dynamic parallelism allows a GPU kernel to launch other kernels, initiating new work while previous work is still in progress. This technique hides latency by enabling additional tasks to run concurrently.
Pipelining: Pipelining divides complex tasks into stages, allowing each stage to begin execution as soon as its inputs are available. This minimizes idle time and ensures a continuous flow of work, reducing latency’s impact.
Kernel Fusion: Kernel fusion involves merging multiple smaller kernels into a single, more substantial kernel. This reduces kernel launch overhead and the time between different kernel executions, thus minimizing latency.
Summary
In this CUDA C++ tutorial chapter, we connected CUDA’s programming model to the way NVIDIA GPUs execute work.
The logical CUDA model (threads, blocks, and grids) becomes hardware work through SMs, warps, and SIMT execution.
Warps are the scheduling unit, so control flow that splits within a warp leads to divergence and reduced throughput.
Resource partitioning (registers and shared memory) limits how many blocks and warps can be active at the same time.
Latency hiding is the main performance strategy: the GPU keeps many warps ready so it can switch to useful work while other warps wait on memory.